
RDD介绍
Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
RDD的4大属性
- partitions: 数据分片
- partitioner: 分片切割原则
- dependencies: RDD依赖
- compute: 转换函数
举个🌰
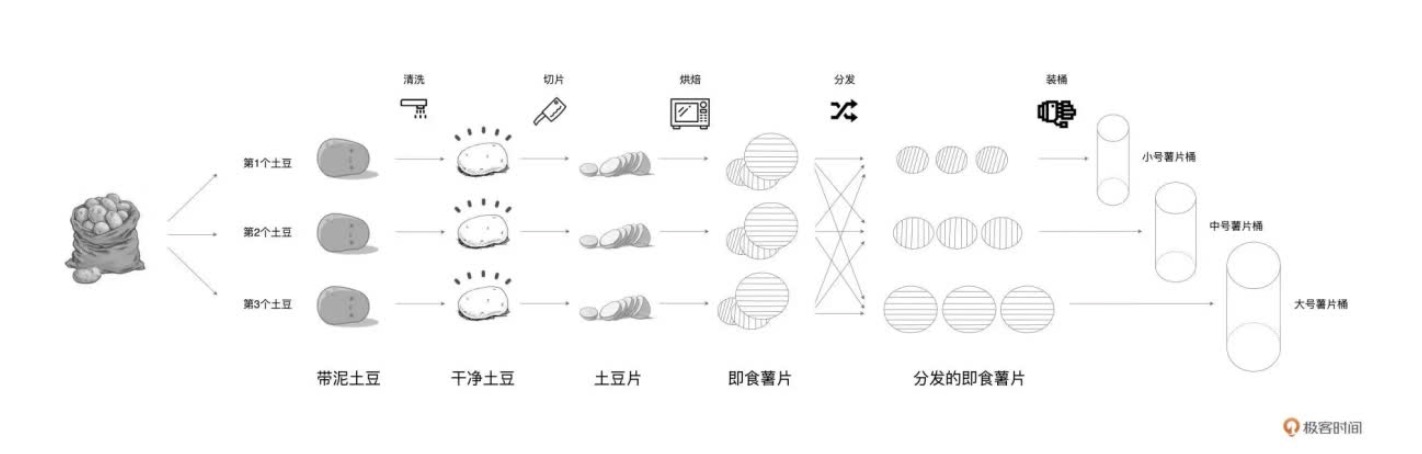
如果把“带泥土豆”看成是RDD的话,那么RDD的partitions属性,囊括的正是麻袋里那一颗颗脏兮兮的土豆。同理,流水线上所有洗净的土豆,一同构成了“干净土豆”RDD的partitions 属性。
我们再来看RDD的partitioner 属性,这个属性定义了把原始数据集切割成数据分片的切割规则。在土豆工坊的例子中,“带泥土豆”RDD 的切割规则是随机拿取,也就是从麻袋中随机拿取一颗脏兮兮的土豆放到流水线上。后面的食材形态,如“干净豆”、“土豆片”和“即食薯片”,则沿用了“带泥土豆”RDD 的切割规则。换句话说,后续的这些RDD,分别继承了前一个RDD的partitioner属性。
这里面与众不同的是“分发的即食薯片”。显然,“分发的即食薯片”是通过对“即食薯片”按照大、中、小号做分发得到的。也就是说,对于“分发的即食薯片”来说,它的partitioner属性,重新定义了这个RDD数据分片的切割规则,也就是把先前RDD的数据分片打散,按照薯片尺寸重新构建数据分片。
由这个例子我们可以看出,数据分片的分布,是由RDD的partitioner决定的。因此,RDD的partitions属性,与它的partitioner属性是强相关的。
RDD依赖和转换
在数据形态的转换过程中,每个RDD都会通过dependencies属性来记录它所依赖的前一个、或是多个RDD,简称“父RDD”。与此同时,RDD使用compute属性,来记录从父RDD到当前RDD的转换操作。
拿WordCount 当中的wordRDD来举例,它的父RDD是lineRDD,因此,它的dependencies属性记录的是lineRDD。从lineRDD到wordRDD的转换,其所依赖的操作是flatMap,因此,wordRDD的compute属性,记录的是flatMap这个转换函数。
简要总结
总结下来,薯片的加工流程,与RDD的概念和4大属性是一一对应的
- 不同的食材形态,如带泥土豆、土豆片、即食薯片等等,对应的就是RDD概念;
- 同一种食材形态在不同流水线上的具体实物,就是RDD的partitions属性;
- 食材按照什么规则被分配到哪条流水线,对应的就是RDD的partitioner属性;
- 每一种食材形态都会依赖上一种形态,这种依赖关系对应的是RDD中的dependencies属性;
- 不同环节的加工方法对应RDD的compute属性。
编程模型和延迟计算
RDD代表的是分布式数据形态,因此,RDD到RDD之间的转换,本质上是数据形态上的转换(Transformations)。
在RDD的编程模型中,一共有两种算子,Transformations类算子和Actions类算子。开发者需要使用Transformations类算子,定义并描述数据形态的转换过程,然后调用Actions类算子,将计算结果收集起来、或是物化到磁盘。
在这样的编程模型下,Spark 在运行时的计算被划分为两个环节。
- 基于不用数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph);
- 通过Actions类算子,以回溯的方式去触发执行这个计算流图。
开发者调用的各类 Transformations 算子,并不立即执行计算,当且仅当开发者调用Actions算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式有个专门的术语,叫作“延迟计算”(Lazy Evaluation)
? 什么是Transformations算子,什么是Actions类算子,需要去查
RDD内的数据转换
Map: 以元素为粒度的数据转换
f, map(f)是以元素为粒度对RDD做数据转换,f可以是带签名的带名函数,或者说匿名函数,如
1 | var kvRDD: RDD[(string, Int)] = cleanWordRDD.map(word => (word, 1)) |
等价于
1 | def f(word: String): (String, Int) = { |
缺点:元素级别,如下需要hash的话,每个元素重复创建hash对象,性能差
1 | var kvRDD: RDD[(string, Int)] = cleanWordRDD.map{word => |
MapPartitions: 数据分区粒度的数据转换
1 | var kvRDD: RDD[(string, Int)] = cleanWordRDD.mapPartitions{ partition => |
FlatMap: 从元素到集合、再从集合到元素
1 | val lineRDD: RDD[String] = _ |
Filter: 过滤RDD
所谓判定函数,它指的是类型为(RDD元素类型) => (Boolean)的函数。
可以看到,判定函数f的形参类型,必须与RDD的元素类型保持一致,而f的返回结果,只能是True或者False。在任何一个RDD之上调用filter(f),其作用是保留RDD中满足f(也就是f返回True)的数据元素,而过滤掉不满足f(也就是f返回False)的数据元素。