布隆过滤器一种空间数据结构,用来判断一个元素是否在某个集合中。由于具有假阳性,所以布隆过滤器只能得出某个元素有可能在该集合,反之该元素一定不在这个集合中。
布隆过滤器简介
一个空的布隆过滤器是一个\(m\)位均为\(0\)的比特位数组,同时定义了\(k\)个哈希函数,将某个元素得出的哈希值映射到m个比特位中的某一位,将该为置为1,生成一个随机的分布。通常\(k\)要远远小于\(m\),\(k\)和\(m\)的选取取决于过滤器的假阳性概率。
添加元素
当给布隆过滤器中添加一个元素时,利用\(k\)个哈希函数得出\(k\)个位置,并将\(m\)个比特位中对应的\(k\)个位置设置为\(1\)。
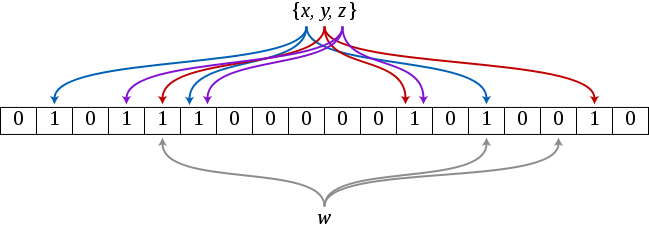
查询元素
查询元素时同样计算出\(k\)个位置,并获取该\(k\)个位置的所有元素值,当有一个位为\(0\)的话,就证明该元素不在该集合里。若\(k\)个位置均为\(1\),则表示该元素可能在集合里,因为某些为\(1\)的位可能是别的元素在插入时设置的。
删除元素
由于假阳性的引入,布隆过滤器是不能删除元素的。
布隆过滤器的优点
链表、哈希表和平衡二叉树都能够做元素的查找,但是布隆过滤器明显在时间和空间利用率上更优
空间利用率
一个拥有1%的错误率和一个优化后的\(k\)的布隆过滤器,存储一个元素只需要\(9.6\)bit,没降低\(1%\)的错误率每个元素也只需增加\(4.8\)bit [文章中写的结论,还需要看证明过程]
时间复杂度
时间复杂度显然是\(O(k)\)
假阳性的概率
假定一个哈希函数选择每个插入位置的概率都是相等的,且位数组一共\(m\)位,那么某个比特位被hash函数不设为1的概率为
$$ 1 - \frac{1}{m}$$
那么通过计算k个哈希函数后,该位不被置为1的概率为
$$ ( 1 - \frac{1}{m} )^k$$
如果该过滤器有n个元素,那么该位为0的概率为
$$ ( 1 - \frac{1}{m} )^{kn}$$
该位为1的概率为
$$ 1- ( 1 - \frac{1}{m} )^{kn}$$
那么随便找k个位置,这些位置都为1的概率(也可认为是假阳性概率)为
$$ (1- ( 1 - \frac{1}{m} )^{kn})^k \approx (1 - e^{-kn/m})^k$$
需要注意的是,该概率不是严格准确的,因为\(k\)个为在被置1时,不是独立事件,但是概率大约是相似的。由此可见,假阳性的概率随着比特位数组长度\(m\)的增大而减小,随着集合元素\(n\)的增大而增大。那么证明了如果\(m\)足够大,布隆过滤器的准确性还是很高的。
如何寻找最适合的k
最适合的\(k\)就是能够使过滤器假阳性的概率达到最低,直观来讲增加哈希函数可以提升准确率,但是又会影响更多的比特位,所以随着哈希函数数量k的增加,假阳性概率或许增加或许减少,因此怎么算最适合的k呢。我们拿出上述得到的概率,假定假阳性概率为\(f\)
$$ f = (1 - e^{-kn/m})^k$$
为了简化运算对$f$取对数
$$ g = ln(f) = k*ln(1 - e^{-kn/m})$$
对其进行求导
$$\frac{dg}{dk} = ln(1 - e^{-kn/m}) + \frac{kn}{m} \frac{e^{-kn/m}}{1 - e^{-kn/m}}$$
当导数为0的时候,就是最适合的k,我们得出最适合的k如下:
$$ k = \frac{m}{n}ln(2) $$
元素数量估算
Swamidass & Baldi提出了布隆过滤器中实际元素估算的方式
$$ n^* = - \frac{mln[1-\frac{X}{k}]}{m} $$
其中,\(n^*\)为元素个数的近似值,\(m\)是位数组长度,\(k\)是哈希函数的数量, \(X\)是位数组中被置为1的位的数量。还没有看完证明过程
总结
布隆过滤器由于引入了假阳性,因此不太适合高精度的需求,业务场景需要能够接受一定错误容忍度,但是查询和插入都是\(O(k)\)的时间复杂度,空间复杂度也相当可观,因此在快速的元素查找定位场景还是大有裨益的。
参考文献
Bloom_filter
Notes 10 for CS 170
Mathematical Correction for Fingerprint Similarity Measures to Improve Chemical Retrieval



